تکنیک های مختلف کش کردن و سیاست های خالی کردن کش
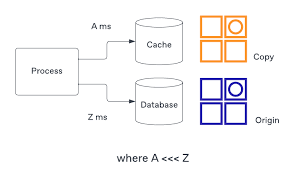
کش کردن تکنیکی است که در علوم کامپیوتر و توسعه وب برای ذخیره و استفاده مجدد از داده های محاسبه شده یا واکشی شده قبلی برای بهبود عملکرد و کاهش تأخیر استفاده می شود. چندین تکنیک کش وجود دارد که هر کدام برای موارد و سناریوهای کاربری خاص طراحی شده اند.
متداول ترین تکنیک های کش:
Memory Cache:
- In memory cache: داده ها در حافظه اصلی سیستم (RAM) ذخیره می شوند. این سریعترین شکل کش است اما مقدار حافظه در آن محدود است.
- کش توزیع شده: داده ها در یک شبکه توزیع شده از کش های حافظه ذخیره می شوند، که اغلب در یک محیط خوشه ای یا مبتنی بر ابر برای دسترسی بالا استفاده می شود.
Page Cache:
- Web page caching: کل صفحات وب از جمله HTML، CSS، جاوا اسکریپت و تصاویر در حافظه پنهان ذخیره می شوند. این باعث کاهش بار سرور و بهبود زمان بارگذاری صفحه برای کاربران می شود.
Object cache:
اشیایی مانند نتایج پرس و جو پایگاه داده، پاسخ های API یا داده های سریالی در کش ذخیره می شوند تا نیاز به محاسبات گران قیمت یا پرس و جوهای پایگاه داده کاهش یابد.
شبکه تحویل محتوا (CDN):
CDN ها دارایی های استاتیک (مانند تصاویر، شیوه نامه ها) را در سرورهای لبه توزیع شده ذخیره می کنند و تأخیر و بارگذاری روی سرور مبدا را کاهش می دهند.
کش کردن دیتابیس:
- کش کردن نتایج پرس و جو: نتایج پرس و جوهای پایگاه داده که اغلب اجرا می شوند برای جلوگیری از دسترسی اضافی به پایگاه داده در کش ذخیره می شوند.
- کش کردن جدول پایگاه داده: کل جداول پایگاه داده یا بخش هایی از جداول برای کاهش بار پایگاه داده در کش ذخیره می شوند.
کش کردن ORM:
- کش کردن نتایج ORM: مجموعههای نتایج از پرس و جوهای ORM (مانند Hibernate، Entity Framework) برای بهبود عملکرد دسترسی به دادهها در کش ذخیره میشوند.
Full-Page chaching:
کل صفحات وب رندر شده، شامل محتوای استاتیک و پویا، برای کاهش بار روی سرور و سرعت بخشیدن به رندر صفحه، در کش ذخیره می شوند.
Proxy server caching:
- Proxy Caching: سرورهای پروکسی میانی، مانند reverse proxyها، محتوای را کش می کنند تا نسخه های کش شده را به کلاینت ها ارائه کنند و لود سرور را کاهش دهند.
Content fragment caching:
بخش های کوچکتر محتوا، مانند بخش های خاصی از یک صفحه وب، برای بهبود زمان بارگذاری برای بخش هایی از صفحه که اغلب به آنها دسترسی دارند، در حافظه پنهان ذخیره می شوند.
Opcode Caching:
- در PHP و زبانهای تفسیری مشابه، ذخیرهسازی opcode بایت کد را در حافظه کامپایل میکند تا از کامپایل مجدد اسکریپتها در هر درخواست جلوگیری کند.
Browser caching:
مرورگرهای وب منابعی مانند تصاویر، شیوه نامه ها و اسکریپت ها را به صورت محلی ذخیره می کنند، بنابراین در بازدیدهای بعدی نیازی به بارگیری مجدد ندارند و زمان بارگذاری صفحه را بهبود می بخشد.
Session caching:
دادههای Session برای جلسات کاربر برای کاهش بار روی Session Store، که اغلب یک پایگاه داده است، در حافظه پنهان ذخیره میشوند.
CDN page chaning:
- Cdn ها میتوانند کل صفحات HTML را در حافظه پنهان نگه دارند، نسخههای کش شده را بر اساس موقعیت مکانی آنها به کاربران ارائه دهند و زمان بارگذاری صفحه را بهبود بخشند.
lazy loading:
به جای بارگیری تمام محتوا از قبل، برخی منابع (مثلاً تصاویر) فقط در صورت نیاز بارگیری می شوند و زمان بارگذاری اولیه را کاهش می دهند.
انتخاب روش کش کردن به کاربرد خاص، نوع داده های ذخیره شده و اهداف بهینه سازی عملکرد بستگی دارد. اغلب، ترکیبی از تکنیک های کش برای دستیابی به بهترین نتایج برای یک برنامه یا سیستم معین استفاده می شود.
سیاست های خالی کردن کش:
سیاست ها یا الگوریتمهای کش کردن مختلف که برای مدیریت موارد کش شده در یک ساختار داده استفاده میشوند. این سیاست ها نحوه ذخیره سازی، بازیابی و خروج موارد از کش را تعیین میکنند. در اینجا برخی از سیاست های رایج کش آورده شده است:
FIF (First in First out)
در کش FIFO، اولین موردی که به کش اضافه می شود، اولین موردی است که پر شدن کش حذف می شود. از یک رفتار مشابه با صف پیروی می کند.
LIFO (Last in First out)
کش کردن LIFO که به آن Stack caching نیز گفته می شود، ابتدا آخرین مورد اضافه شده را حذف می کند. از یک رفتار پشته مانند پیروی می کند.
LRU (Least Recently Used):
کش کردن LRU زمانی که حافظه پنهان پر است، آیتمی که اخیراً کمتر استفاده شده است را حذف می کند. این مبتنی بر این ایده است که اگر به یک مورد اخیراً دسترسی پیدا نکرده باشد، احتمال کمتری وجود دارد که به زودی دوباره از آن استفاده شود.
LFU (Least Frequently Used):
کش کردن LFU زمانی که کش پر است، مواردی که کمتر استفاده می شود را حذف می کند. تعداد دفعات دسترسی به هر آیتم را شمارش میکند و موردی را که کمترین فرکانس دسترسی را دارد بیرون میکند.
MRU (Most Recently Used):
کش کردن MRU آخرین مورد استفاده شده را هنگامی که حافظه پنهان پر است حذف می کند. این برعکس ذخیره سازی LRU است.
جایگزینی تصادفی:
سیاست جایگزینی تصادفی یک مورد ذخیره شده در کش را به طور تصادفی برای تخلیه زمانی که حافظه پنهان پر است انتخاب می کند. الگوهای دسترسی یا سابقه استفاده را در نظر نمی گیرد.
2Q (Two-Queue)
استراتژی ذخیره سازی 2Q دو صف جداگانه را حفظ می کند، یک صف پرکاربرد (F1) و یک صف که اخیراً استفاده نشده است (F2). آیتم های جدید در F1 قرار می گیرند و وقتی دوباره به آنها دسترسی پیدا می شود به F2 منتقل می شوند. اخراج از F2 رخ می دهد.
ARC (Adaptive Replacement Cache):
ARC یک سیاست کش تطبیقی است که به صورت پویا اندازه حافظه پنهان را بر اساس عملکرد خطمشیهای LRU و LFU تنظیم میکند. هدف آن ترکیب نقاط قوت هر دو سیاست برای بهبود نرخ بازدید حافظه پنهان است.
Clock (یا شانس دوم)
Clock caching نوعی از FIFO است که از یک بافر دایره ای استفاده می کند. بر اساس بیت مرجعی که هنگام دسترسی به آیتم تنظیم میشود، قبل از بیرون راندن، «شانس دوم» داده میشود.
MQ (چند صف):
کش چند صفی، صف های متعددی را با اولویت های مختلف حفظ می کند. اقلام بر اساس الگوهای دسترسی خود در صف های مختلف قرار می گیرند و ابتدا از صف های با اولویت پایین تر خارج می شوند.
انتخاب سیاست کش به مورد استفاده خاص و الگوهای دسترسی داده ها بستگی دارد. برخی از خطمشیها، مانند LRU و LFU، در سناریوهای خاص مؤثرتر هستند، در حالی که برخی دیگر، مانند جایگزینی تصادفی، ممکن است زمانی استفاده شوند که هیچ الگوی دسترسی خاصی شناخته نشده باشد یا زمانی که سادگی ترجیح داده میشود. مکانیسمها و سیاستهای کش متفاوتی برای بهینهسازی عملکرد و استفاده از منابع برای یک برنامه یا سیستم معین انتخاب میشوند.
منبع:
https://medium.com/@aggarwalapurva89/different-caching-techniques-660ad8d97a8a